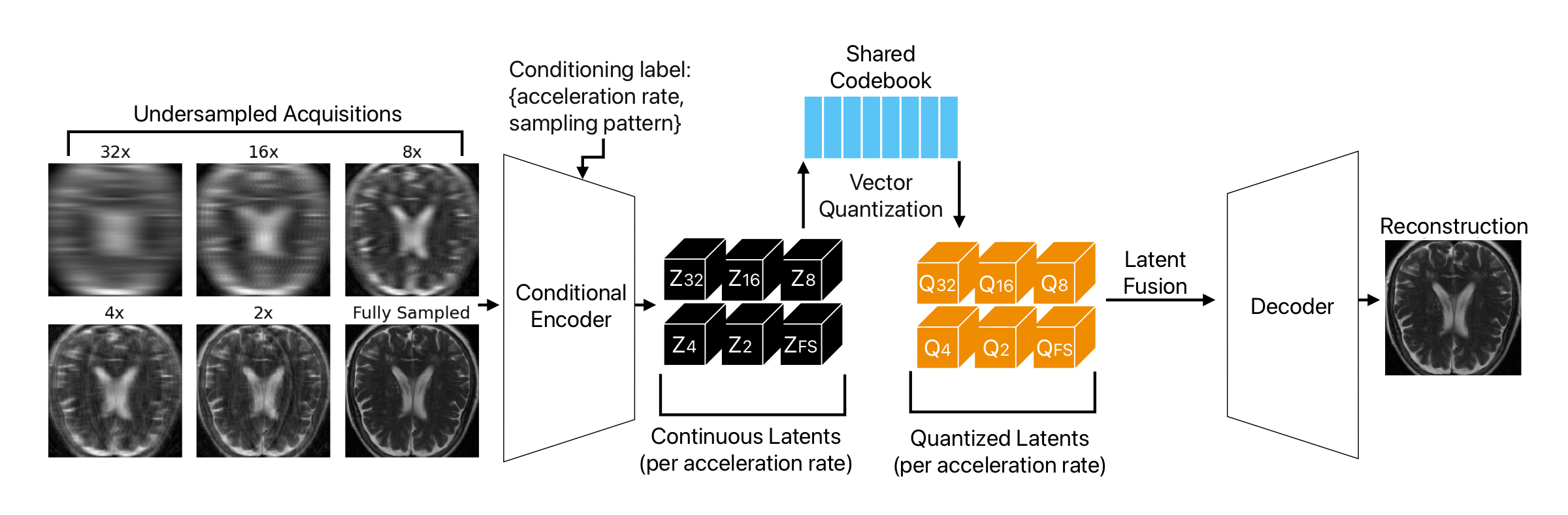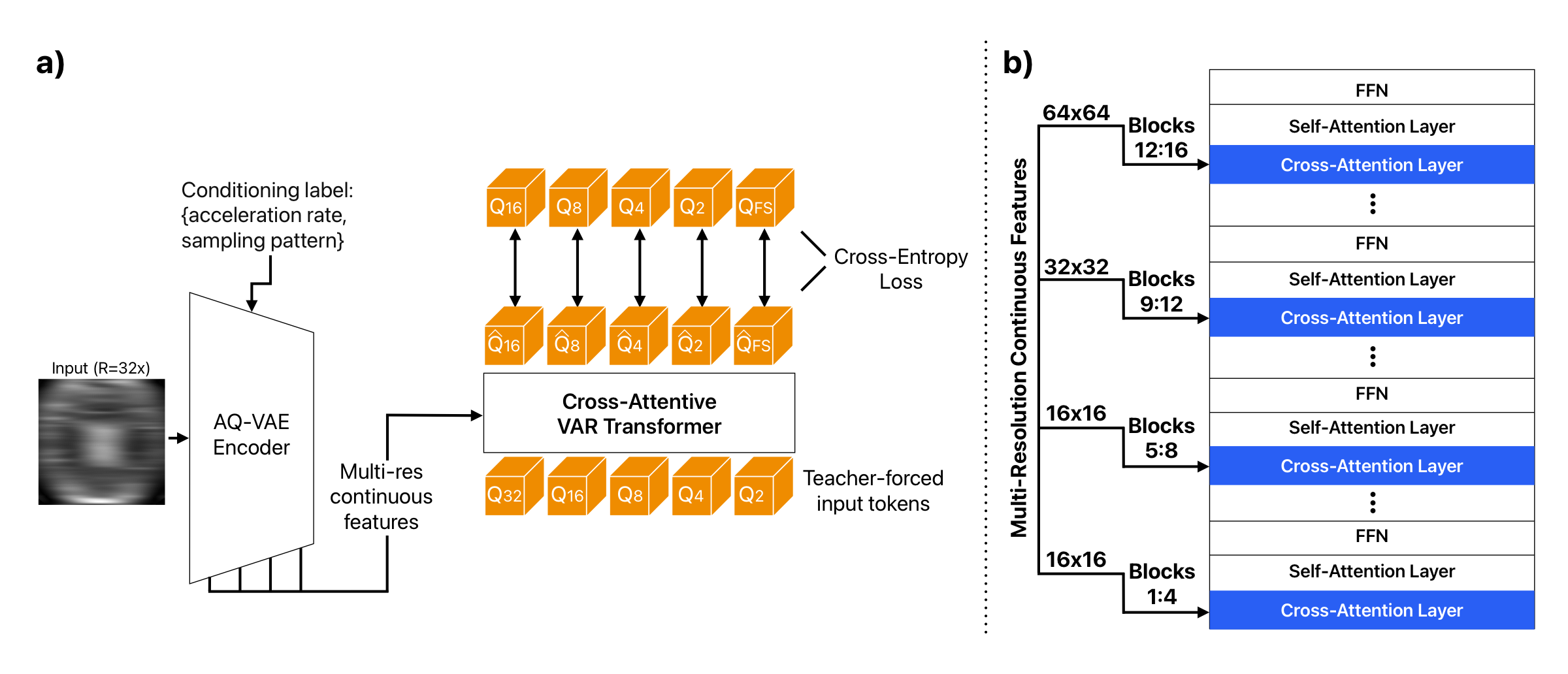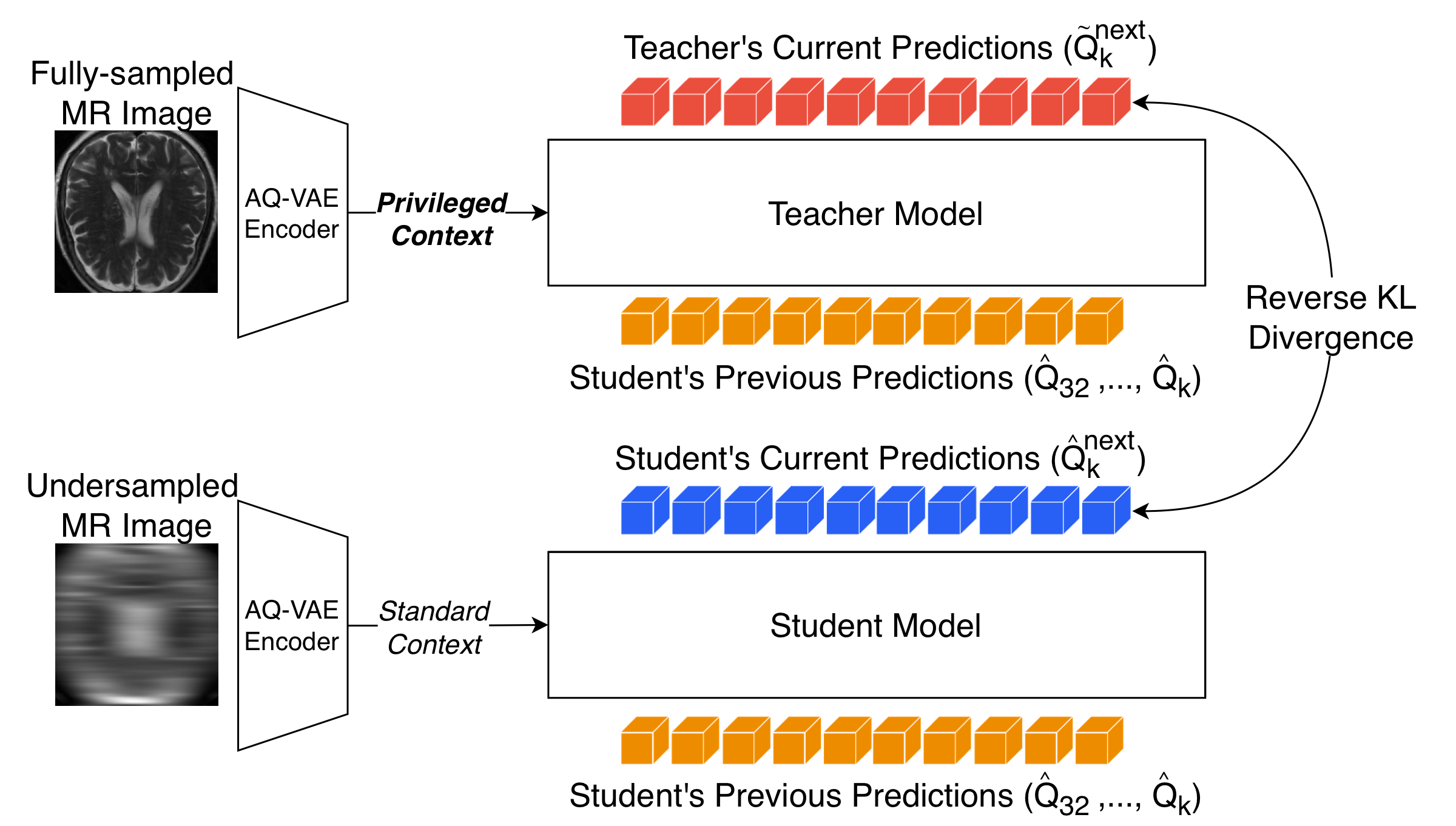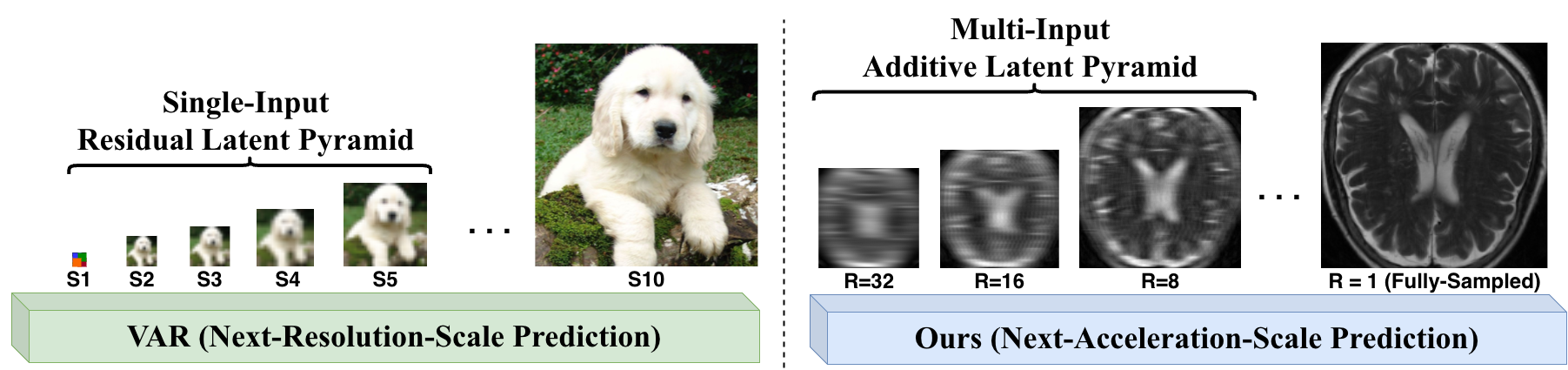
Overview. Instead of generating a residual latent pyramid from one image as in VAR, the proposed method induces a hierarchy before encoding by applying MRI-native Fourier undersampling at different acceleration factors. This turns accelerated MRI reconstruction into next-acceleration-scale prediction from sparse measurements toward the fully sampled acquisition. |